Kevin D. Johnson
HPC+AI Infrastructure · Neuromorphic Computing · Quantum-Centric Supercomputing · Forward-Deployed Engineering
Recent Focus Areas
Where infrastructure meets intelligence.
Palantir Foundry / AIPThree integrations — entity discovery + ontology enrichment, multi-modal targeting, and autonomous ontology generation via SymWisdom. |
LLM & Gen AI InfrastructurevLLM, GPFS KV cache sharing, semantic routing, Nemotron-120B reflection engine, multi-LLM orchestration at scale. |
Neuromorphic & Heterogeneous Compute10-chip AKD1000 hive mind, QPU+NPU+GPU+CPU orchestration, sub-millisecond edge inference across 12 silicon architectures. |
Autonomous Ontology DesignSystems that discover, name, and structure concepts from continuous perception — no human modeling required. |
Data Platform ArchitecturePetabyte-scale GPFS, mmap’d shared state across 11 nodes, experience lifecycle management, three-tier KV cache replacing Redis. |
Forward-Deployed Engineering13 years delivering to government, research, financial services, healthcare, and life sciences. |
Technical Papers
Peer-style research on heterogeneous compute orchestration, neuromorphic systems, and quantum-classical integration.
Symphony as Compute Ontology: Extending Insight into OpenShift and NVIDIA AI Factories
April 2026
Presents IBM Spectrum Symphony as the compute ontology for OpenShift and NVIDIA AI factory infrastructure, formalizing the categorical distinction between container placement engines and compute ontologies. ELIM delivers typed resource metrics with semantic direction, consumer hierarchies provide unlimited-depth organizational governance with sub-second rebalancing, SOAM manages service lifecycles with per-phase failure policies, and cross-substrate routing spans OpenShift clusters, bare-metal GPU hosts, cloud burst instances, and heterogeneous accelerators under one workload management domain. A detailed comparison with Kueue (v0.17) demonstrates that Kubernetes’ strongest governance extension operates at alpha API maturity with zero capability in five of six ontological dimensions. A feature-complete analysis of Run:ai (v2.24) establishes that every Run:ai capability is replicable within Symphony’s ELIM architecture using exclusively public GPU APIs. Three engagement modes — Ontology Enrichment, Ontology Governance, and Ontology Subsumption — accommodate extending the compute ontology into OpenShift without modifying the container platform. Part I of two; a companion paper will present empirical validation across three compute substrates.

Solving the One and the Many with LSF, Symphony, GPFS, and RHEL AI: A Dynamic Compute Platform for NVIDIA AI Factories
March 2026
Presents a multi-ontology architecture for AI factory workload management where IBM Spectrum LSF manages batch training, IBM Spectrum Symphony manages service-oriented inference, and IBM Storage Scale (GPFS) serves as the unified coordination substrate connecting the two compute domains. RHEL AI and vLLM provide the model serving runtime across NVIDIA, AMD, and Intel accelerators. Five demonstrations on commodity hardware validate the architecture, including multi-model vLLM inference, neuromorphic routing at 622 microseconds, cross-model KV cache transfer with 8.2x latency improvement, 47-second model handoff, and an Obfuscation-as-a-Service pipeline. Complements the earlier Sovereign AI OS paper, together spanning from neuromorphic workloads to large-scale GPU training and inference into Foundry.

Extending the Sovereign AI OS: Symphony as Compute Ontology for Palantir Foundry and NVIDIA
March 2026
Extends the Palantir-NVIDIA Sovereign AI OS Reference Architecture with IBM Spectrum Symphony as a heterogeneous compute orchestrator, enabling neuromorphic processors, quantum resources, edge sensors, and mainframe systems to participate as peer compute tiers alongside GPUs within Foundry’s governed ontology framework. Four working demonstrations validate the extension across autonomous ontology construction, cross-modal neuromorphic fusion, multi-paradigm trust verification, and AI-enabled financial ontology discovery.

High Performance Quantum-Centric Supercomputing: A Working Implementation of Heterogeneous Orchestration across QPU, NPU, GPU, CPU, and Other Tiers
March 2026
A reference architecture demonstrating that traditional batch schedulers require a fundamentally different approach for heterogeneous quantum-classical resources. Extends IBM Spectrum Symphony with proof-of-concept evidence across fifteen demonstrations spanning twelve silicon architectures, six compute tiers, and two network fabrics — orchestrating QPU, NPU, GPU, CPU, and mainframe as peer resource types under a single scheduling domain.

Commentary
Articles on AI infrastructure, neuromorphic computing, and the architecture of intelligence.
Fiction
Short stories — usually about bourbon, silicon, or both.
Technical Demonstrations
53 demonstrations built between December 2025 and June 2026.
The demonstrations span the BrainChip Akida neuromorphic platform and a compute ontology stack built on IBM Spectrum Symphony, LSF, and Storage Scale (GPFS). Together they cover six industry domains, eight technology themes, and a range of standout results, from autonomous missile defense and a 120-chip special-operations hive mind to a functional artificial brain reproduced across the AKD1000 fleet. The accompanying analysis segments every demonstration by industry, by technology, and by what is most notable, most innovative, and most unique relative to the broader market.
The Demonstration Program: A Segmented Analysis
June 2026 · 2 pages
A two-page analysis of the full demonstration program, segmenting the first 51 builds by industry and domain, by underlying technology, and by what stands out as most notable, most innovative, and most unique relative to the broader market. Industry coverage runs from defense and national security through financial services, healthcare and public health, critical infrastructure, information integrity, and AI infrastructure. Technology themes span neuromorphic LLM serving and inference, hive-mind distributed consensus, on-chip and online learning, heterogeneous quantum-classical orchestration, real-time sensor fusion, encrypted cognition and provenance, autonomous ontology construction, and the Symphony, LSF, and GPFS orchestration substrate. A closing market-position table contrasts each capability against what the broader market offers today.

Full Demo List
| Date | Demonstration | Platforms |
|---|---|---|
| June 15 | Emulating the Interpretive Mind: A Council of Neuromorphic Brains Reading Scripture across Jewish, Christian, and Islamic Traditions — Cerebra, the BrainChip, Symphony, and GPFS platform that runs as a council of neuromorphic brains in the design of Peter van der Made, was turned on a problem most artificial intelligence avoids, namely the interpretive faculty of a human mind rather than mere pattern matching. Where the dominant approach treats the mind as one large model and large language models dominate the field, the brain is instead a federation of specialized regions that perceive, disagree, and reconcile, and interpretation, the act of reading the same text and arriving at genuinely different meanings, is among the hardest things that federation does and the faculty a single model imitates least convincingly. For this demonstration each neuromorphic brain was steeped in a different interpretive tradition, one in Jewish rabbinic and Talmudic sources, one in the Christian church fathers and the scholastics, and one in the Qur’an and its classical commentary, and I gave all three the same foundational passages, the binding of Isaac, the Shema, and the Genesis creation account, then measured what in the text surprises, what bonds two traditions together, and where their readings genuinely part. The result is not a label or a score but a map of where interpretation itself diverges, presented in plain language a reader can follow without decoding a single number, and the pattern that emerged is consistent and recognizable, the Jewish and Christian readings tracking each other most closely while the Islamic reading stands distinctly apart across all three passages, a structure the architecture was never told to expect and instead discovered. The substrate is the point as much as the result, each mind running a temporal state-space language model on BrainChip Akida neuromorphic silicon that processes information as sparse events at a small fraction of the power a GPU would draw, Symphony orchestrating the three fleets as one multi-tenant fabric and GPFS carrying the shared memory the minds use to exchange their conclusions, no mind swapping places with another and none a copy of its neighbor, each holding its own specialization and a cognition shaped by its tradition. The same machinery that locates where interpretations diverge applies to legal language, to contested policy text, and to the detection of rhetoric that bends a shared source toward an extreme reading, and emulating a mind proves to be a matter of structure, specialization, disagreement, and reconciliation running on a substrate efficient enough to sustain many minds at once, with no foundation model to train and no mountain of GPUs, indeed no GPU involved in this demonstration at all. ▶ video | NPU (AKD1000 + Akida v2 SDK simulation, three federated sites), temporal state-space language model, interpretive-tradition specialization, divergence mapping, Symphony, GPFS, IBM Cloud |
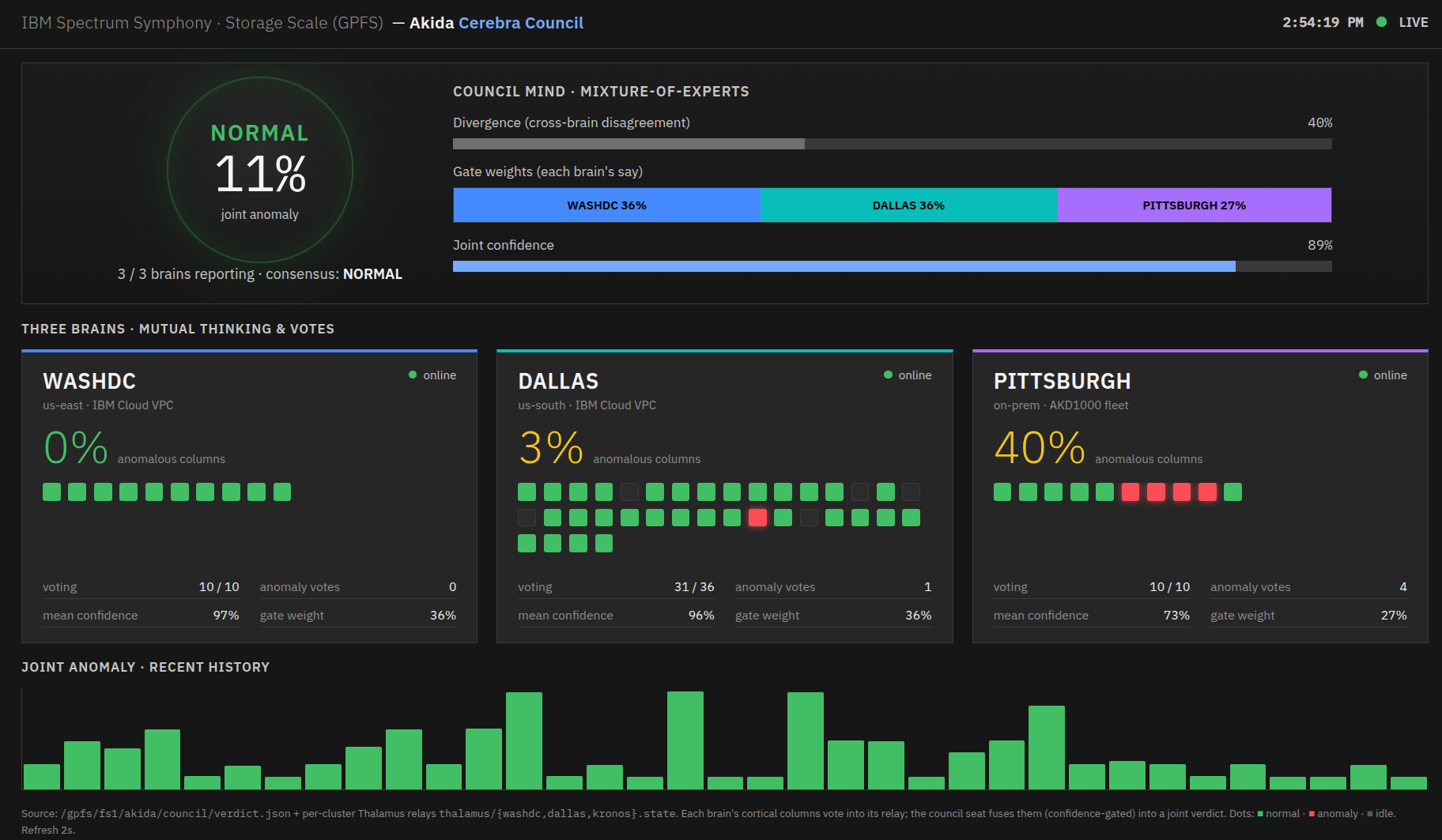
| June 14 | A Neuromorphic Council: Three Synthetic Cortexes in Washington, Dallas, and Pittsburgh Reaching Consensus across the Continent — Three independent synthetic cortexes, separated by thousands of miles, were brought online to perceive, learn, and reach consensus together, one brain in Washington, DC, one in Dallas, and one in Pittsburgh, three minds engaged in a single shared act of thinking with no GPU anywhere in the system. Each brain runs a synthetic cortical-column architecture on BrainChip Akida, the event-driven silicon that computes in spikes rather than matrix multiplications, learning online and continuously at milliwatts with no training run and no model to retrain overnight; the architecture is Peter van der Made’s and the contribution here is giving it three instantiations and several states to think across, adding scale. Each brain perceives not with cameras but with radio, using WiFi Channel State Information to sense presence and motion from the way human bodies perturb the ambient wireless signals already filling every room, so the building itself becomes the sensor. Inside each brain many cortical columns independently judge how surprising the current moment is and cast a vote, a thalamus relays those votes into a local consensus, and because the columns never stop learning, today’s surprise quietly becomes tomorrow’s normal without overwriting the past; a mixture-of-experts council then fuses the three brains into one shared verdict, weighing each by its confidence and surfacing divergence, the moment one brain notices something the other two do not, treated not as noise but as the system paying attention. IBM Cloud carries the sites, IBM Spectrum Symphony marshals the fleet, and Storage Scale (GPFS) serves as the shared memory binding the federation, a heterogeneous compute ontology that makes neuromorphic hive-mind capability possible at continental scale, intelligence living not inside one enormous model in one datacenter but as many small brains perceiving locally, learning forever, and thinking together, running right now. ▸ screenshot | NPU (AKD1000 + Akida v2 SDK simulation, three federated sites), WiFi CSI sensing, online learning, mixture-of-experts consensus, Symphony, GPFS, IBM Cloud |
| June 11 | Cerebra: Sensing Presence through WiFi on a Self-Organizing Neuromorphic Mesh across the AKD1000 Fleet — Cerebra is the name now given to the buildout of Peter van der Made’s full functional-brain design across a real Symphony and GPFS cluster, the architecture and credit his, the cluster engineering the contribution here, and because a brain generalizes, the same ten neuromorphic nodes that learned to read rail traffic were turned to an entirely different task, each node fitted with a small AR9271 WiFi radio and allowed to self-organize into a sparse multi-hop mesh that routes around itself. The radios then become a sense organ, since a WiFi signal carries a per-frequency fingerprint of the space it crosses, so Cerebra was taught the empty-room fingerprint and learned online with no labels, reporting movement, placement, and presence with no camera, no GPU, and nothing worn, the novelty signal rising only on the sensor nearest the person and staying flat on the far ones, tracking a person across a room and across two floors. What matters is that Cerebra builds a model of normal, is surprised by the new, votes across many nodes for consensus, and does not forget the old as it learns the new, so any abnormality such as an unexpected presence is flagged rather than a crude motion alarm, pointing toward a nervous system for a forty-floor building, neither the edge nor the data center, but wherever generalized intelligence that learns is needed. | NPU (AKD1000 x10), AR9271 WiFi mesh, online STDP learning, Symphony, GPFS |
| June 11 | A Functional Artificial Brain: Peter van der Made’s Full Neuromorphic Vision across the AKD1000 Fleet — In celebration of the fiftieth demonstration, and a day after reproducing Peter van der Made’s foundational 2007 proof-of-concept, the complete neuromorphic vision from his book Higher Intelligence: How to Create a Functional Artificial Brain was reproduced, and the design works. His actual neuron was rebuilt rather than approximated, with receptor registers that leak at neurotransmitter-specific rates, a variable threshold that rises after each spike, STDP-BCM learning that fires only when the neuron does, and winner-take-all inhibition; on it sit structural plasticity that grows new neurons without forgetting the old, glial pruning during sleep, neuromodulation, long-term consolidation, and a predict-sense-update loop in which each column anticipates the next input and learns only when surprised, organized into the larger organs he describes, a Thalamus that relays, a Hippocampus that consolidates, a Limbic system that turns novelty into attention, and a Cortex of columns that vote. Ten BrainChip AKD1000 chips perform the spiking inference in silicon, one per node, with the recurrent pieces the 2007 silicon could not express running on an Akida 2 simulation tier beside them, IBM Spectrum Symphony orchestrating one service per chip, and GPFS serving as the lock-free shared nervous system where the columns post their votes, a hive mind in which no chip is in charge and meaning crosses the wire through shared state; overnight at one Tennessee rail junction it classified live video frame by frame across more than eighteen thousand classifications, rebuilt the passing railcars into whole trains, and taught itself the routine coal and intermodal traffic with no labels and no retraining, rating the ordinary as ordinary and flagging the unusual that no classifier was trained to catch. Almost twenty years ago it was ten tones on ten neurons; today it is a fleet of neuromorphic chips learning the world from live video, the way van der Made said a brain should work, trained rather than programmed. | NPU (AKD1000 x10 + Akida 2 sim), Synthetic Neuro-Anatomy, STDP-BCM, structural plasticity, Symphony, GPFS |
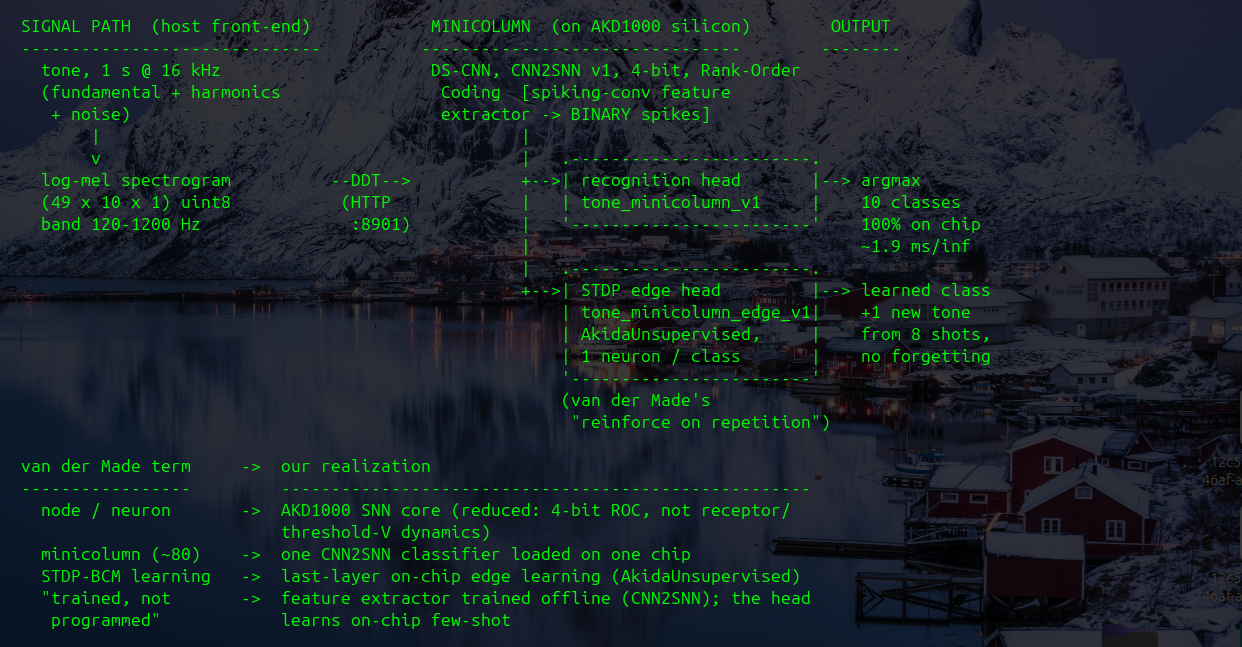
| June 10 | Reproducing Akida’s Foundational On-Chip Learning: Van der Made’s 2007 Tone-Recognition Proof-of-Concept across the AKD1000 Fleet — In 2007 Peter van der Made built an FPGA that learned rather than ran a program, his Synthetic Neuro-Anatomy architecture (the ancestor of BrainChip’s Akida) teaching itself to recognize musical tones on-chip from repetition alone, with no labeled dataset and no backpropagation. Working through his paper, the original ten-tone proof-of-concept (10 notes, 220 to 587 Hz) was reproduced on a production AKD1000 running over Symphony and GPFS at 100 percent accuracy and roughly 1.9 ms per inference, then extended across all ten AKD1000 chips in the fleet. The STDP learning acquires a new tone on the chip as its defining feature while retaining the other nine, reinforcement on repetition in hardware with no retraining run, no GPU, and no round-trip to a datacenter, a skill learned in milliseconds on-device from a handful of examples at sub-milliwatt power. ▸ screenshot | NPU (AKD1000 x10), Synthetic Neuro-Anatomy, STDP, Symphony, GPFS |
| June 10 | Distilling TENNs-LLM-1b onto Akida: A Chip-Sized Student Served via vLLM and Grounded in Retrieval — BrainChip’s TENNs-LLM-1b, a 1.24-billion-parameter selective state-space model that cannot convert to Akida directly today, was distilled into a small linear state-space student that shares its 32k vocabulary, converts to a single Akida model, and serves through vLLM, answering the capital of France as Paris on the neuromorphic stack with output identical to the native SDK. The real capability is a division of labor in which the chip-sized model handles the skill while retrieval carries the knowledge, so the combined system answered every fact correctly, including unseen ones the model alone never gets, with updates made by editing a file through a skill that runs at milliwatts. The recipe is general, distilling any teacher onto a fleet of kilobyte-to-megabyte specialists stored once on GPFS, hot-swapped and routed by Symphony, and grounded in private data, in BrainChip’s MetaTF simulation today with chips to follow. | NPU (Akida v2 sim), vLLM, Symphony, GPFS, IBM Cloud |
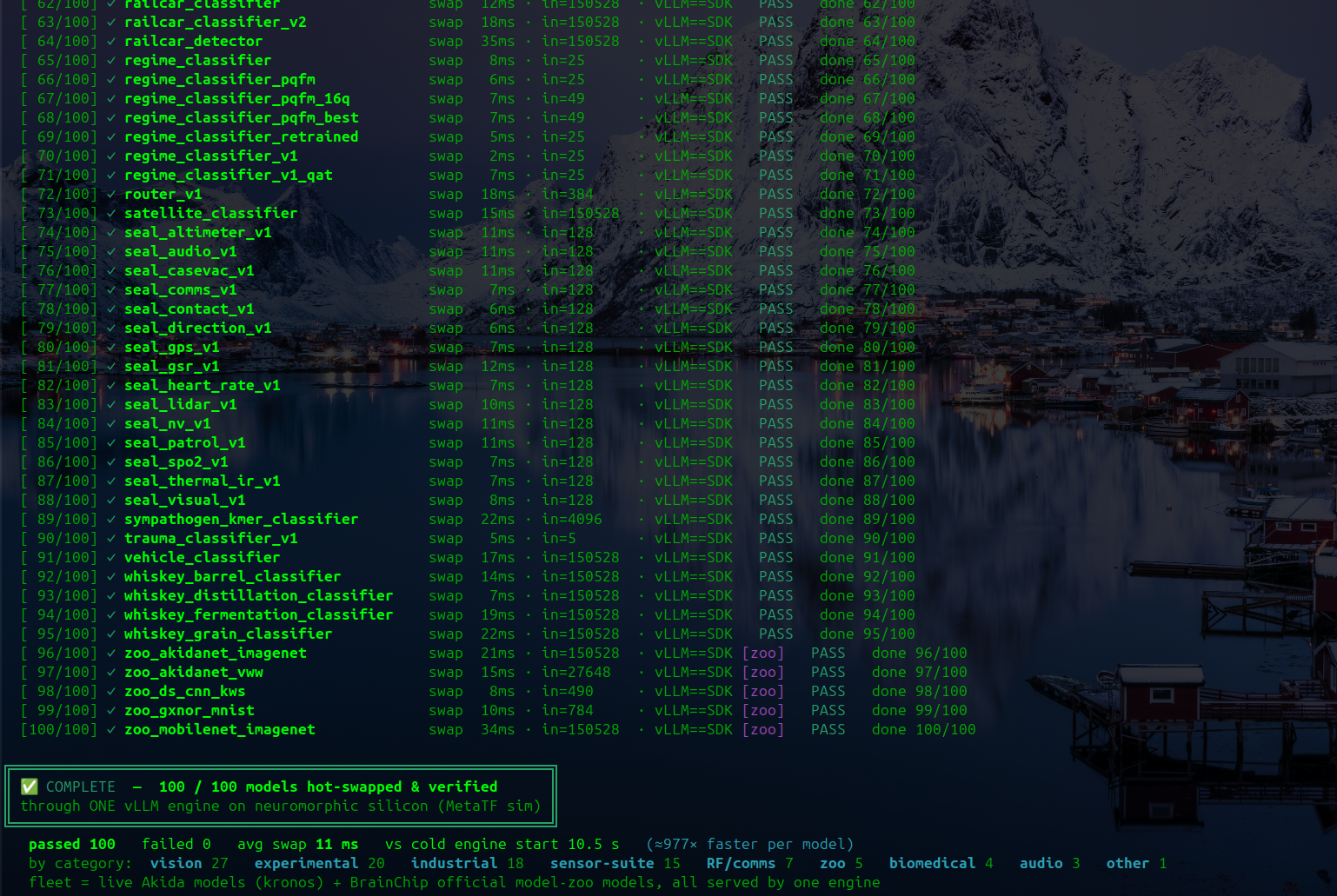
| June 9 | Hot-Swapping 100 Models on vLLM: Decoupled Model Load across the Akida Fleet — Because the model load on the chips, real or simulated, is decoupled from vLLM’s engine, models hot swap in and out very quickly, and a short Python script swapped 100 models one after another at an average of 11 ms each on IBM Cloud. A full library of models can therefore stay available at any time across ten AKD1000 N100 nodes running Symphony and GPFS, hosting all 100 models on each node, switching any one out on demand through the multi-model, multi-modal, multi-domain Akida services, and remaining reachable by enterprise AI through the same OpenAI interface vLLM affords on platforms like Red Hat’s Inference Server or RHEL AI, on-premises, in the cloud, or both. ▸ screenshot | NPU (Akida v2 sim), vLLM, Symphony, GPFS, IBM Cloud |
| June 9 | TENNs-LLM-1b on vLLM: Serving BrainChip’s Billion-Parameter State-Space Language Model — BrainChip’s TENNs-LLM-1b, a one-billion-parameter general-knowledge language model built as a state-space model of 24 gated TENNs blocks rather than a transformer, now serves through the same vLLM plugin as a second backend, requiring no new engine code because the design already separates starting and scheduling vLLM from running the model behind the worker. The model answers through /v1/completions token-for-token with its own runtime so anything that already speaks vLLM can call BrainChip’s LLM today, while a parallel effort distills the selective input-dependent model into a linear, today-convertible state-space student that shares its vocabulary and maps straight onto the current neuromorphic stack ahead of the chip-native silicon of BrainChip’s next-generation Akida GenAI line. | NPU (Akida v2 sim), vLLM, Symphony, GPFS, IBM Cloud |
| June 8 | Akida as a First-Class vLLM Backend: Neuromorphic Inference behind the Standard Serving API — A plugin built for BrainChip’s neuromorphic Akida platform makes the chips a first-class serving backend for vLLM on Symphony with GPFS. vLLM is the de facto enterprise serving layer for language models, the inference server behind Red Hat AI, owning queries, batching, sampling, and the OpenAI API that the surrounding ecosystem already speaks, so a model meant for the data center, on-premises, or the cloud should speak vLLM. The plugin makes Akida a first-class peer alongside GPUs: vLLM owns the API surface while the plugin hands each forward pass to the Akida SDK running models on-chip. One serving surface carries two model classes end-to-end, a generative byte-level language model that decodes autoregressively token by token, and a fleet of classifiers and detectors for the neuromorphic hive mind. Nine models have been exercised so far, served as several different .fbz packages without per-model code, fitting the multi-model, multi-modal, multi-domain Akida and Symphony capability already in place. The same /v1/completions and /classify endpoints that clients already call are now answered by event-driven, int8, milliwatt-class silicon rather than a GPU, so nothing downstream changes: a dashboard, a RAG pipeline, a semantic router, or anything else that speaks vLLM can route work to neuromorphic chips transparently. Symphony orchestrates chip allocation across the fleet alongside the vLLM presence on the grid so both scale horizontally, and GPFS serves as the shared model store and coordination substrate, letting one plugin reach from a single chip to a cluster of them the same way the heterogeneous 20-chip network behaves as one substrate for the neural network. The work remains simulation today with silicon next, yet the serving path holds end to end, vLLM in front and Akida underneath, with Symphony organizing it and GPFS providing linear scale. | NPU (Akida v2 sim), vLLM, Symphony, GPFS, IBM Cloud |
| June 4 | Heterogeneous Neuromorphic LLM: A 1B-Parameter Model Run Across 20+ Akida Chips as One Network — Using IBM Spectrum Symphony with BrainChip Akida v2 simulation and TENNs-PLEIADES, a fleet of neuromorphic chips is assembled to behave like a single neural network, and a one-billion-parameter byte-level language model is run across it. The stack decomposes a language model by function and maps each function to a chip: temporal mixing, namely how tokens relate over time, runs on TENNs-PLEIADES state-space chips, while channel mixing, roughly 99 percent of the weights and compute, runs on convolutional chips. The orthogonal-polynomial kernels of TENNs-PLEIADES run as a streaming, causal, constant-memory state-space model with no growing KV cache, so sequence modeling runs indefinitely at the edge where attention cannot go. Symphony chains the two kinds into a heterogeneous pipeline, the int8 output of one chip streaming into the next, so the model becomes more than 20 cooperating chips in BrainChip’s MetaTF simulation, trained end-to-end and exercised with a real query fed token-by-token through the whole pipeline. The central idea is that the 20-plus chips are not separate accelerators; together they are one neural network, where the inter-chip links are its edges and the chips are its layers, so the hardware topology is the model. To the author’s knowledge, a billion-parameter LLM run as a heterogeneous, function-specialized multi-chip neuromorphic network has not been demonstrated before; the setup remains simulation before silicon, yet the architecture holds end-to-end and puts streaming inference on milliwatt-class silicon. | NPU (Akida v2 sim x20+), TENNs-PLEIADES, MetaTF, Symphony |
| June 3 | SymGrayZone: Cognitive-Warfare Analysis of the U.S. Data-Center Backlash — SymGrayZone examines whether the United States data-center backlash is organic or steered, framed on the Válka-Mír Research Foundation’s cognitive-warfare doctrine and run on real data: 571 Bluesky posts, 241 X posts, 32 Facebook posts, seven bills, and multi-pass funding research, with the analysis constrained so that an honest “organic” verdict remained reachable. The doctrine holds that a gray-zone operation does not manufacture grievance; it finds a real fissure, amplifies it, and steers it toward action, with the money structured so that attribution never resolves. Five analytical layers map to that cascade: the grievance is real, with roughly 70 percent of Americans opposed to a nearby data center; the discourse has been organized and nationalized through a scripted advocacy template, a co-posting cohort beyond chance (z = +6.7), and synchronized protest language across 32 states; no covert botnet appears, since cross-platform timing synchrony reached 5.6 sigma but collapsed to -0.2 sigma once news-event windows were removed; the seven statute texts show near-zero verbatim overlap, evidencing independent drafting; and the money is foreign-national in deniable cover, with Wyss (Swiss) alongside Hohn, Oak, KR, and Quadrature funding the ecosystem through anonymizing pass-throughs while Chinese state media amplifies only reactively. The verdict is a genuine bipartisan grievance, nationalized by an organized domestic campaign, likely funded through legitimately sourced foreign-national money in classic deniable cover, and opportunistically amplified by a foreign state, which is the doctrine’s own prediction that a well-run gray-zone operation and no operation at all produce the same public evidentiary signature. SymGrayZone builds on the SymVulnerability pattern (BrainChip Akida, Symphony, and GPFS). | NPU (AKD1000 x10), Symphony, GPFS |
| May 29 | SymHelmet on a G1 Squad: Neuromorphic Hive-Mind Consensus with Drone Overwatch — The neuromorphic hive mind first demonstrated on the SEAL helmet (an extension of symseal and symhelmet) now drives a squad of ten simulated Unitree G1 humanoid robots, each walking on reinforcement-learning gait policies with the real physics of the G1 platform fully in play. An overwatch drone spots an ambush at range and warns the hive; the ten G1s autonomously break formation into defensive positions seconds before the enemy comes into sight, then engage from those prepared lines once the ambush springs. No human sits in the loop: the drone perceives, the hive reaches consensus, and the whole squad maneuvers, all driven by the same BrainChip AKD1000 neuromorphic fabric on Symphony. Each robot perceives through ten AKD1000 neuromorphic chips, and the motion of the swarm feeds 110 chips live into a distributed hive mind that reads the formation and calls the regime, resolving the squad status from PATROL to CONTACT by consensus once the hive recognizes the enemy. Physics-balanced gait and genuine hive-mind consensus run on the same fabric demonstrated on the helmet, with crouch positions training next, and the mechanics already working. ▶ video | NPU (AKD1000 x110 sim), Unitree G1 (x10 sim), RL gait policy, Symphony |
| May 28 | Akida on IBM Spectrum LSF: Batch Scheduling for the Neuromorphic Fleet — In honor of the LSF Community Summit in Santa Clara on June 1, the demonstration runs BrainChip AKD1000 chips under IBM Spectrum LSF rather than Symphony, trading the service-oriented model for batch scheduling on the same neuromorphic fleet; LSF is widely used across semiconductor design and large-scale language model training spanning thousands of nodes and multiple clusters worldwide. ELIMs expose each Akida to LSF as a custom schedulable resource that reports whether a chip is free, which model is currently mapped, and which tenant last used it, turning LSF into an informed workload manager that coordinates multi-tenant access cleanly, pre-warms models on available chips, and keeps the fleet duty cycle high. Running LSF and Symphony together over a compute ontology that avoids single-vendor GPU lock-in lets the same low-power fleet absorb scheduled batch work overnight and serve online inferencing by day. | NPU (AKD1000 x10), Intel N100, IBM Spectrum LSF |
| May 26 | SymVulnerability: Computational Development of Community-Scale Radicalization Risk — A holiday-weekend research build combines a serious historical case with Patrick James Christian’s psychosocial perspective into a predictive framework for community-scale vulnerability. The 1918 influenza pandemic killed roughly 280,000 Germans in the first wave; over a decade later, Germany voted the National Socialist German Workers’ Party into power, with a 2020 New York Fed report by Blickle supplying several economic explanations for that connection. The larger question driving the demonstration was whether the traumatic historical event is measurable outside of Blickle’s economic analysis and whether the radicalization of large segments of society can be predicted; SymVulnerability answers that question via computational development, where building the coordination substrate is the research itself rather than mere preparation. BrainChip Akida AKD1000 silicon runs the trauma and propaganda classifiers natively, IBM Spectrum Symphony orchestrates six composed services alongside SymGenome and others, and IBM Storage Scale (GPFS) federates twelve OCR’d Reich yearbooks (1917 through 1933), model files, and other historical data. Blickle’s research was reproduced by examining the city-level spending panel rebuilt from cluster-OCR’d yearbooks and publicly available historical data, with Jürgen Falter’s per-city religious-affiliation panel added as a moderator that explains why certain cities voted the way they did, and with Patrick James Christian’s literature on the epidemiology of violent extremism and radicalization (available at the Válka-Mír Research Foundation) supplying the psychosocial accounting that turned the capability predictive. Blickle’s correlation is a fit to Weimar Germany; Christian’s cascade is a theory of how community-scale vulnerability develops independent of country, era, or trigger; reproducing that theory via computational development is what makes it operational. The forward-prediction panel covers 318 US cities, combines 2020 COVID-19 mortality with ARDA religion census data, and flags present-day risk; the Akida fleet runs as a neuromorphic hive mind, ten chips inferring continuously and re-estimating as new data lands, and the panel updates itself with risk scores day by day. SymVulnerability is a defensive community-scale vulnerability measurement rather than a political exercise designed to score points against any American political side. Computational development compressed years of research into a weekend so radicalization risk can be watched day by day going forward. ▶ video | NPU (AKD1000 x10), CNN2SNN, Symphony, GPFS |
| May 22 | SymGenome II: Federated Outbreak Detection across Clinical Sequencing Sites — Part II of the SymGenome federated pathogen surveillance work, demonstrating cross-site outbreak detection through moment-by-moment federation of genomic sequencing wherever it occurs nationwide: each clinical sequencing site keeps a rolling per-organism baseline on a local AKD1000 chip at sub-millisecond per genome with no batching, and when a site’s own rate for a given organism crosses two standard deviations above its baseline the federation marks the site primed, which lowers the detection threshold for that organism at every other site from sigma at least 3 down to sigma at least 1, collapsing the CDC PulseNet 16-day single-cluster median into a same-cycle finding. Five independent Akida models per isolate, with different k-mer feature spaces, different architectures, and no shared training distribution, supply 3-of-5 agreement at detection time, replacing the 2 to 4 week post-hit follow-up cycle (sequence typing, clinical correlation, cross-lab review) with cross-model corroboration in the same evaluation pass. The demonstration network used 19 chips (10 real, 9 simulated), handled the full nationwide genomic sequencing volume historically available for the two pathogens covered, and a replay of the 2020 Salmonella Newport outbreak across 20 then 100 simulated sites surfaced 7 then 29 additional jurisdictions that would never call single-site sigma at least 3, opening real-time cross-pathogen co-occurrence flagging and sub-day actionable multi-site alerts in roughly 85% of US jurisdictions whose local sequencing rate is otherwise too sparse to fire. ▶ video | NPU (AKD1000 x10 silicon + 9 sim), CNN2SNN, Symphony, GPFS |
| May 19 | SymGenome: Two-Site Federated Pathogen Surveillance with Symphony Overflow to IBM Cloud — Two-site genomic demonstration for federated pathogen surveillance, with a CNN2SNN classifier on k=6 k-mer composition vectors (12 classes covering ESKAPE, common foodborne, hantavirus, and other) running as the same 2.4 MB .fbz package on physical AKD1000 silicon near Pittsburgh and on the IBM Cloud “Overflow” cluster in Washington, D.C., behind an identical POST /predict API and reaching 91% test accuracy across 87,720 windows on real silicon within 0.05 percentage points of the keras-quantized baseline. Symphony moves workload elastically between the two sites under policy-led control (PA overflows to DC during a local crisis or retrospective sweep, DC repatriates back to PA once pressure clears, no human trigger required), GPFS coordinates the shared data layer beneath both substrates, and PHI-bound raw sequence data stays local at each site while only classification metadata crosses the federation. The test scenario replays the 2020 Salmonella Newport outbreak (over 1000 illnesses across 48 states), partitioned temporally across the two sites and played back in time order, examining whether the federated baseline self-organizes before either site alone reaches statistical confidence. | NPU (AKD1000 silicon + simulation), Intel N100, CNN2SNN, Symphony, GPFS, IBM Cloud |
| May 17 | SymEventCamera: Vehicle Classification on Akida via IP Cameras as Event-Sensor Drop-In — Four off-the-shelf IP cameras feed a vehicle classification pipeline running on BrainChip Akida’s neuromorphic substrate, reaching 98% per-frame capture on cars. The pipeline is engineered as a drop-in path for true event cameras; replacing the source adapter is the only change required when real event hardware arrives, while the encoder, the model, the runtime, and the orchestration stay the same. Each camera streams a 640×360 H.264 sub-stream at 10 Hz; a log-intensity frame-difference encoder thresholded at three sigma emits two binary channels (brighter pixels and darker pixels) resembling what a hardware event sensor produces. A 15-frame sequence then runs through a TENNs Pleiades model on the Akida v2 SDK. Symphony pins each camera to its own inference node at sub-second end-to-end latency with ample headroom for scaling camera duty far beyond four streams. The generic Akida simulation service gained a new sequence-aware /predict_sequence endpoint that takes the whole 15-frame tensor in one call, resets temporal state up front, and returns a majority-vote classification, without touching the existing single-frame /predict path used by the cluster’s CNN tenants. The objective is recognizing a moving vehicle across a temporal sequence rather than a still car in a single frame; the same model runs unchanged whether the upstream is an IP camera with a software encoder or a true event sensor producing the sparse, motion-shaped input that Akida was designed to process. ▶ video | NPU (Akida V2 SDK x4 sim), TENNs Pleiades, RTSP IP cameras, Symphony, GPFS |
| May 12 | SymCanon Speed Demo: Hotel California at 168 BPM — Raw performance speed of the neuromorphic hive mind music system, running Hotel California at 168 BPM versus the song’s normal 74 BPM. Ten BrainChip AKD1000 chips actually perform the score at the faster tempo, not a playback speed-up, with Symphony scheduling thousands of microsecond-scale inference decisions across the fleet and the ceiling set by human listener perception rather than the silicon. ▶ Hotel California Fast video | NPU (AKD1000 x10), Intel N100, Symphony, GPFS |
| May 9 | By Request: Neuromorphic Hive Mind Music, Comfortably Numb and Hotel California — Extension of the March 11 hive mind music demo. 10 AKD1000 chips as ensemble, each trained on distinct catalog slices; the fleet took requests from listeners and produced Pink Floyd’s Comfortably Numb and the Eagles’ Hotel California, with each chip contributing its trained voicing into the combined performance under Symphony orchestration across Intel N100 nodes and GPFS-shared catalog assets. ▶ Comfortably Numb video ▶ Hotel California video | NPU (AKD1000 x10), Intel N100, Symphony, GPFS |
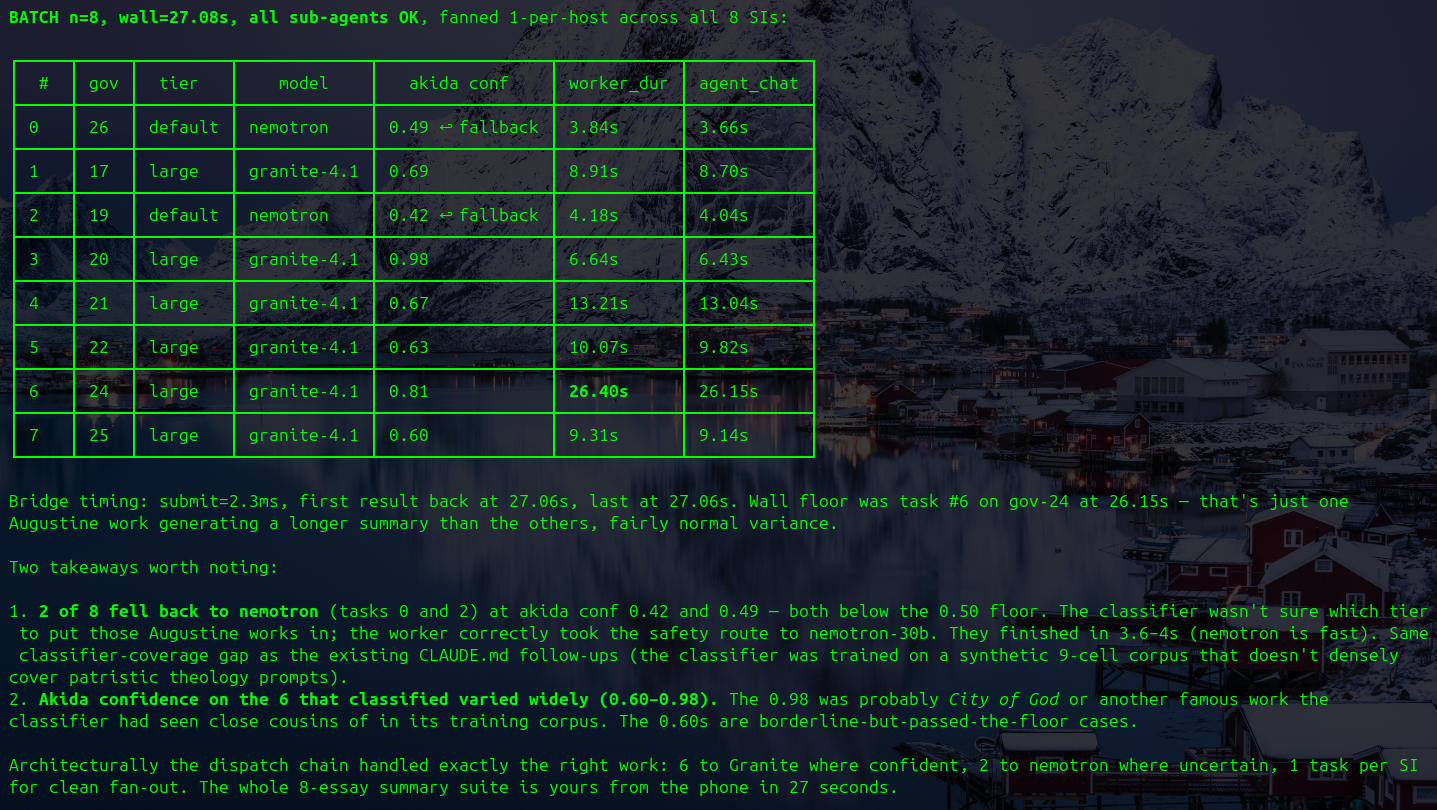
| May 8 | SymHermes: Phone-Driven Multi-Agent Fan-Out with Akida Routing — Using Telegram, a message sent (“summarize the major works of Augustine”) landed in the Hermes orchestrator, which fanned out 8 parallel sub-agents across 8 Symphony nodes. Each sub-agent was routed in roughly 5 ms by neuromorphic AKD1000 chips to the appropriate model tier, Granite 4.1 on IBM Cloud or Nemotron on-prem, keyed by confidence level. The full multi-agent reply returned to the phone in 27 seconds end-to-end, with neuromorphic dispatch latency essentially invisible against LLM inference time. The refinement over the initial pass, including newer Granite 4.1 models, added performance checks, and Symphony plus Akida properly invoked in the fan-out path, produced dramatic improvement versus the first run. vLLM tuning and back-end model selection still leave further headroom. The architecture: phone → Telegram → Hermes orchestrator → Akida-routed sub-agent fan-out → Symphony-scheduled inference across IBM Cloud Granite models and on-prem Nemotron, end-to-end conversational throughput in roughly half a minute. ▸ screenshot | Nous Research Hermes, NPU (AKD1000 x8), AMD EPYC, NVIDIA GPU (vLLM, Nemotron), Symphony, GPFS, IBM Cloud (Granite 4.1), Telegram |
| May 4 | SymSEAL: Neuromorphic Hive Mind for Special Operators — Ten special operators share a single neuromorphic perception layer, including drone overwatch, with twelve real BrainChip AKD1000 chips per helmet and 120 across the team under a 30-watt envelope per helmet. Symphony orchestrates the 120 inference units as one perceptive layer; GPFS serves as the cognitive substrate, providing distributed consensus across operator nodes. The concept parallels Anduril Industries’ EagleEye, however the AKD1000 chips and Symphony/GPFS together deliver an actual neuromorphic substrate sufficient to constitute a real hive mind, scaling identically from ten helmets and 120 chips to a hundred helmets and one thousand chips. The AKD1000 fires spikes at milliwatts; the hive identifies threats in microseconds to milliseconds; operator reaction remains bounded by motor neuron conduction velocity at 50 to 100 m/s and the seconds-scale pull from cortex through aim, intent, and trigger. The next-generation play would be closed-loop auto-fire driven by the hive itself, with the operator’s intent still up front and Rules of Engagement still binding the engagement; the hive accelerates the loop and does not replace the operator. The architecture is built and running today, traversing real BrainChip silicon alongside a simulated chip fabric, all routing through a combat simulation. A second demo will follow showing Anduril Industries’ Lattice and Palantir Technologies’ Foundry wired in for the engagement, including two tactical units operating concurrently with mission archetypes recognized across both engagements at once. ▶ video | NPU (AKD1000 x12/helmet, 120 total + simulated fabric), Intel N100, AMD EPYC, Symphony, GPFS, Palantir Foundry, Anduril Lattice, ARMA 3 |
| Apr 25 | FireMesh: Neuromorphic Wildfire Detection across Public Satellite Data — Palisades Fire replay shows the pipeline classifying every hot pixel from GOES-18, VIIRS, MODIS, and GLM as wildfire or confounder in roughly three milliseconds on simulated BrainChip Akida V2 chips with no GPU and no cloud round-trip. Symphony orchestrates the ingest layer: services pull FIRMS every 60 seconds, decode GOES FDCA every 5 minutes, and fetch L1b radiance via S3 byte-range so a 5 KB slice replaces a 160 MB scan. Decoded products land on GPFS shared storage, mounted across every node so the same bytes serve historical playback and live inference together. Detections fan into a 36-node Akida fleet: three nodes serve a tabular FIRMS classifier, thirty-three run a spatial L1b model trained on six historical California fires and gas-flare negatives from the Permian, Bakken, and Eagle Ford. 3.5 ms per classification, 8 KB of weights, edge-deployable without an NVIDIA card. The harder story is not speed but discrimination: wildfire versus refinery flare versus ag burn versus metal-roof reflection, the difference that makes the alert worth sending. AKD1500 silicon path could project the same orchestration onto a verdict stream that ICS section chiefs, county OES, and mutual-aid dispatch could subscribe to with geo-fenced AOR, confidence, and latency surfaced inline. ▶ video | NPU (Akida V2 SDK x36 sim), Symphony, GPFS, AWS S3 (GOES-18, VIIRS, MODIS, GLM), NASA FIRMS, NASA Earthdata/LAADS (VIIRS VNP14IMG), Copernicus Data Space STAC (Sentinel-1/2/3, Landsat), USGS EROS M2M, Cal Fire DINS, LA County assessor parcels, MTBS burn perimeters/dNBR, Mapillary street-view, PurpleAir, AirNow, OpenSky ADS-B, Wingbits, AISStream |
| Apr 19 | Shattered Crown in Anduril Lattice: Full-Chain C2 Integration — The Ardenath: Codex of Portents rendering migrated from the original parchment interface into Anduril Industries Lattice, driven by live BrainChip Akida v2 classifications from SymWisdom’s Symphony cluster and the same self-assembling ontology in Palantir Foundry. The full chain now runs Lattice, Akida, Symphony, NVIDIA LLM, Foundry, and GPFS as a single integrated pipeline. Integration completed in about three hours, bridging data flow between platforms. Lattice does not render fantasy maps because it is a production C2 platform involved in real military work; 31 Banner Lords and the Waystones monitoring them were positioned in open Pacific waters, transformed from the original Stable Diffusion parchment with its auto-drawn borders, and redrawn in fine tactical fashion in Lattice. 36 nodes with 36 Akida 1500 simulations run real-time, while continuous neuromorphic perception classifies a synthetic theater and drives the map’s function. The operator sees both activity and coordination with full provenance attribution back to Foundry. The architecture enables policy-led command and control alongside neuromorphic experience and collected wisdom crystallization as the system continues to operate. ▸ screenshot | Anduril Lattice, Akida V2 SDK (TENNs-PLEIADES) x36 sim, KVM fleet, Symphony, GPFS, Nemotron Cascade 30B, Palantir Foundry |
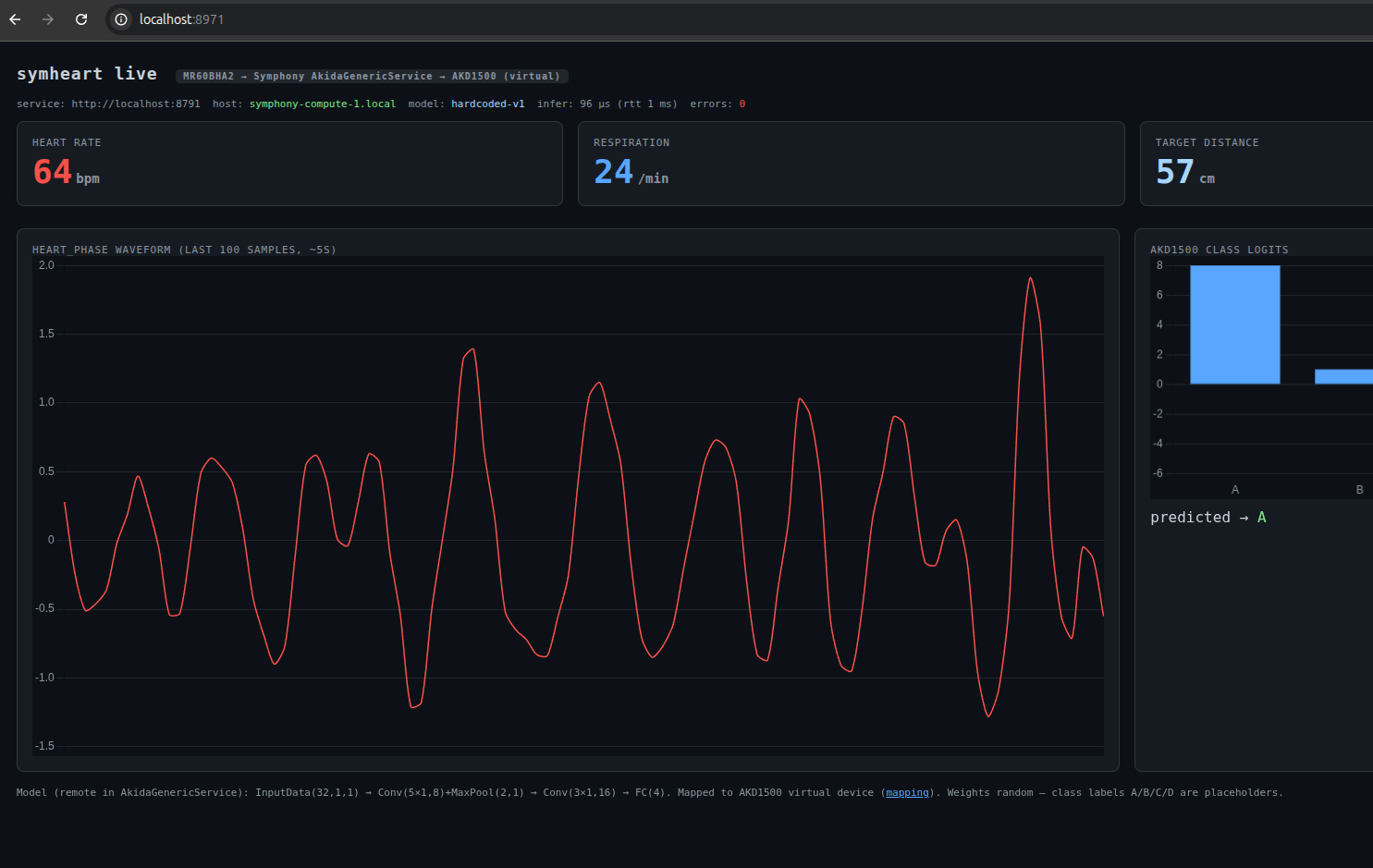
| Apr 18 | SymHeart: Vital-Signs Biometrics on Symphony Community Edition — Seeed Studio MR60BHA2 60 GHz mmWave Human Breathing and Heartbeat Sensor streaming into a simulated BrainChip AKD1500 through Symphony Community Edition, a four-node Docker Symphony cluster running on a laptop. Live dashboard shows heart rate (64 bpm), respiration (24/min), target distance (57 cm), a 5-second heart-phase waveform, and AKD1500 class logits from the remote AkidaGenericService. Model pipeline: InputData(32,1,1) → Conv(5×1,8)+MaxPool(2,1) → Conv(3×1,16) → FC(4), mapped to the AKD1500 virtual device at ~96µs inference. Live demonstration at the BrainChip booth, Microelectronics US 2026, April 22 and 23. ▸ screenshot | NPU (AKD1500 sim), mmWave sensor (Seeed MR60BHA2), Symphony Community Edition, Docker |
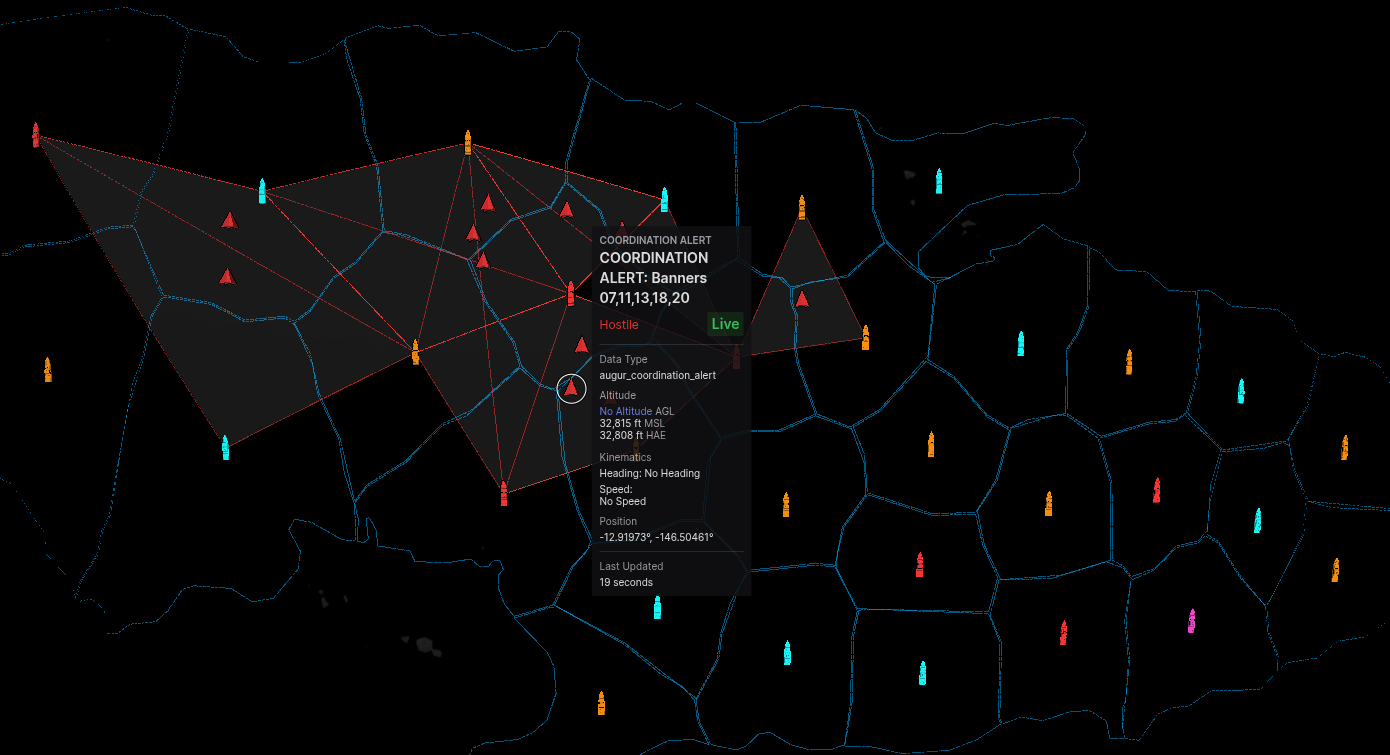
| Apr 16 | Ardenath: Codex of Portents — Neuromorphic Loom on a KVM Fleet — Kingdom of the Shattered Crown: a fantasy frame for a 36-chip simulated Akida 1500 fleet running TENNs-PLEIADES across 36 KVM instances. 31 Waystones and 5 sworn watch regional Banner Lords across an ink-drawn continent; a council of Augurs keeps vigil. Each simulated chip listens for nine distinct behavioral signatures in its assigned region, feeling neuron spike patterns fire. Symphony orchestrates every node; GPFS binds the shared observational substrate so no two chips see different versions of the truth. Nemotron Cascade (30B) reflects on edge activity and Banner Lord coordination; an ontology crystallizes itself into Palantir Foundry without manual definition — the same self-assembling pattern used by SymWisdom and SymRail. The identical architecture already runs against 10 real AKD1000 chips watching American freight rail economics at ~1 mW per inference, whiskey distillery fermentation on a rotating partition, and OSINT across ten aggregated modalities. ▶ video ▸ full writeup | Akida V2 SDK (TENNs-PLEIADES) x36 sim, KVM fleet, Symphony, GPFS, Nemotron Cascade 30B, Palantir Foundry |
| Apr 11 | Akida V2 SDK Capacity Demo: Symphony Across On-Prem + IBM Cloud — Capacity and scaling demo of the BrainChip Akida 1500 V2 SDK across three independent Symphony clusters: an on-prem EPYC Rome VM fleet, a 10-node IBM Cloud Symphony in Washington DC (Cascade Lake bx2-4×16), and a 36-node IBM Cloud Symphony in Dallas. TENNs-PLEIADES spatiotemporal model. Per-physical-core throughput converged at ~90 inf/sec ±5% across all baselines; per-context RAM 40.6–40.8 MB (within 0.3%); cross-cluster scaling 99.4% of ideal. The combined 46-node IBM Cloud fleet held 8,832 concurrent V2 inference contexts in ~349 GB aggregate RAM. Demonstrates Symphony as a horizontal scaling substrate for neuromorphic V2 simulation: hardware-deterministic and linearly scalable across cloud regions. AKD1500 silicon path projected at 32k–160k inf/sec per chassis (32 chips, ~10 W) — one silicon chassis ≈ 4–19× the 46-node cloud sim fleet at ~1% of the power. | Akida V2 SDK (TENNs-PLEIADES), EPYC Rome, Cascade Lake (bx2-4×16), Symphony, IBM Cloud (WashDC + Dallas) |
| Apr 9 | SymRail: Neuromorphic Freight Intelligence — 10 live Railfan cameras across the United States feed frames to 10 AKD1000 chips, each assigned a camera location from Rochelle, Illinois to Folkston, Georgia. 9-class railcar classifier (tank cars, intermodal containers, grain hoppers, coal hoppers, autoracks, boxcars, empty flats, locomotives, no train) trained via transfer learning from ImageNet backbone. V1 hit 85.6% on hardware; V2 reached 91% after augmenting with 4,247 auto-labeled crops from a YOLOv8n detector, quantized to 4-bit weights and activations fitting in 1 MB SRAM. Spike records flow through shared memory into GPFS archives. Tank car counts at strategic junctions are a leading indicator for petroleum logistics — comparable freight visibility to satellite data services costing >$50k/yr, generated from public cameras on neuromorphic chips. Flask dashboard with live US map. ▶ video | NPU (AKD1000 x10), NVIDIA GPU (YOLOv8n), Symphony, GPFS, Palantir Foundry |
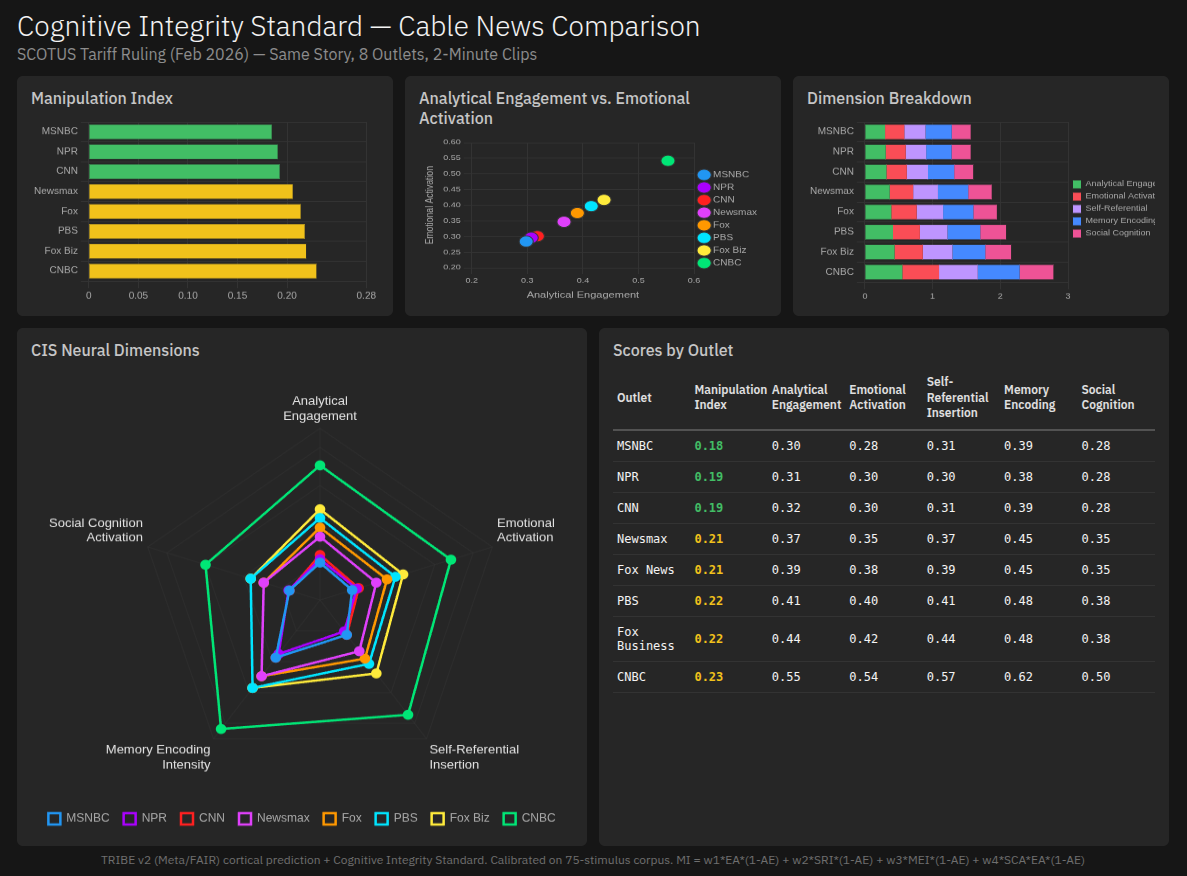
| Apr 3 | Cognitive Integrity Standard: Neural Media Scoring — Quantitative framework measuring what media content does to the brain during processing. Meta/FAIR TRIBE v2 multimodal brain encoding model predicts cortical activation across 20,484 vertices; 10 AKD1000 chips run custom spiking neural nets for real-time EEG signal processing trained on clinical EEG datasets (Temple University Hospital, CHB-MIT, Siena, PhysioNet, DTU). Five neural dimensions — Analytical Engagement, Emotional Activation, Self-Referential Insertion, Memory Encoding Intensity, Social Cognition Activation — combine into a Manipulation Index where every term includes (1 – Analytical Engagement): content that engages critical thinking mathematically cannot score as manipulative. Scored eight outlets’ coverage of the Supreme Court’s 6-3 tariff decision. CNBC and Fox Business scored highest across every dimension — markets are personal, money is emotional, and financial reporting engages the prefrontal cortex. Opinion-heavy cable (MSNBC, CNN) scored lowest on analytical and emotional activation alike, suggesting low overall cortical engagement rather than manipulation. Normalization calibrated against a 75-stimulus corpus spanning six content categories. ▸ results | NPU (AKD1000 x10), NVIDIA GPU (TRIBE v2), Symphony, GPFS |
| Apr 2 | SymIntercept: Autonomous Missile Defense — Full kill chain in under 200ms: sensor fusion, threat classification, trajectory prediction, interceptor dispatch. Counters hypersonic glide vehicles and saturation attacks at Mach 7+. Rules of Engagement defined as Foundry ontology objects — queryable, auditable, version-controlled policy propagated to the edge. Cryptographic provenance via CKKS homomorphic encryption with QRNG-seeded Shamir secret sharing for N-of-M independent sensor confirmation. 10 AKD1000 chips classifying IR blooms, radar returns, and EW signatures in under 1ms at milliwatts. Two scenarios: single-radar refusal (provenance blocks engagement) and multi-sensor confirmed intercept from four defense assets. TTS narration via Qwen3-TTS. ▶ video | NPU (AKD1000 x10), NVIDIA GPU (Qwen3-TTS), Symphony, GPFS, Palantir Foundry, OpenFHE |
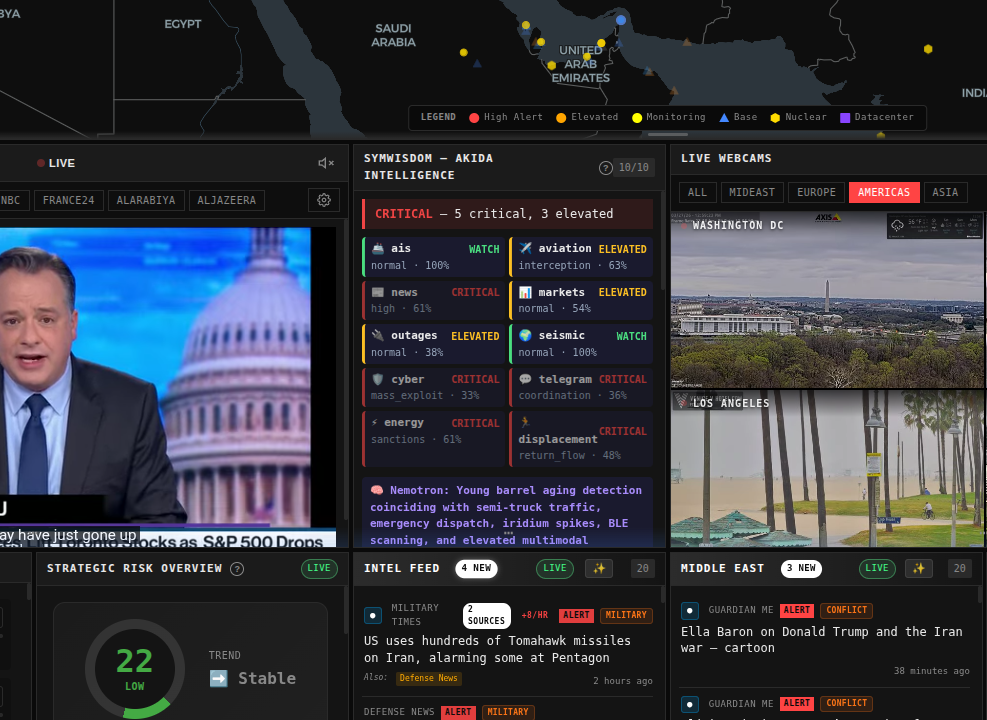
| Mar 27 | SymWisdom WorldMonitor: Akida Intelligence Panel — 10 geopolitical OSINT domains (maritime AIS, aviation, news, markets, infrastructure, seismic, cyber, Telegram, energy, displacement) classified by 10 AKD1000 chips in sub-microsecond inference at ~10μJ. Three-domain model swap in 31ms via GPFS scheduler. ELIM-driven autonomic scheduling: critical domain count and focus mode as Symphony resource metrics trigger GPU scaling, premium feed acquisition, and crisis posture shifts. Built in one day. ▸ screenshot | NPU (AKD1000 x10), NVIDIA GPU (vLLM), Symphony, GPFS, Palantir Foundry |
| Mar 25 | SymPalantir RAG: Trust Architecture for RAG Poisoning — Four-layer trust pipeline for RAG ingestion: cryptographic signatures, multi-party approval, Nemotron-120B semantic review, and neuromorphic anomaly detection on 10 AKD1000 chips (9ms). Embeddings encrypted end-to-end via CKKS homomorphic encryption. Full attack-then-defense scenario with TTS narration. Built in three days. ▶ video ▸ full writeup | NPU (AKD1000 x10), NVIDIA GPU (Nemotron-120B), Symphony, GPFS, Palantir Foundry, IBM Quantum |
| Mar 24 | NeuroDOOM 50: 50 Simultaneous DOOM Instances on 10 AKD1000 Chips — 50 VizDoom instances on the same 10 chips; All orchestrated by IBM Spectrum Symphony with Ozzy Osbourne crossover audio from the hive mind music demo. The hive mind scales. ▶ video | NPU (AKD1000 x10), Intel N100, Symphony, GPFS |
| Mar 23 | SymWisdom Part II: Encrypted Multi-Domain Cognition — Homomorphic encryption at consciousness boundary via OpenFHE/IBM Quantum, multi-domain neuromorphic swap (defense + whiskey distillery) across 15 models, 6-phase self-introspection framework, 3,845 reflections, 13 wisdom objects including first cross-domain object ▸ full writeup | NPU (AKD1000 x10), NVIDIA GPU (vLLM), Symphony, GPFS, Palantir Foundry, IBM Quantum, OpenFHE |
| Mar 20 | SymWisdom: The Experiencing LLM — 10 AKD1000 chips perceiving across 7 modalities, Nemotron-120B reflecting every 45 seconds, 6 wisdom objects crystallized into Foundry from 1,646 reflections in 40 hours ▸ full writeup | NPU (AKD1000 x10), NVIDIA GPU (vLLM), Symphony, GPFS, Palantir Foundry |
| Mar 16 | NeuroDOOM: Hive Mind Learns to Play DOOM — 10 AKD1000 chips as hive mind playing DOOM; ~4ms per-chip inference, 35fps real-time at ~10W total. Plays DOOM so fast it’s hard to watch. ▶ video | NPU (AKD1000 x10), Intel N100, Symphony, GPFS |
| Mar 11 | Neuromorphic Hive Mind Music — 10 AKD1000 chips as ensemble, each trained on distinct catalog slices; played Pachelbel’s Canon in D and Ozzy Osbourne’s Crazy Train ▶ Canon video ▶ Crazy Train video | NPU (AKD1000 x10), Intel N100, Symphony, GPFS |
| Mar 4 | Non-Extractive Targeting with Symphony, Akida, and Foundry — 10-chip multi-modal sensor fusion across 7 modalities with Symphony emergence engine writing confirmed events to Foundry; built in five days ▶ video ▸ full writeup | NPU (AKD1000 x10), Symphony, GPFS, Palantir Foundry |
| Feb 20 | Neuromorphic Deepfake Voice MFA — Three-layer auth: KeyCloak OIDC/JWT, Akida voice biometric (109μs, 92.6%), adversarial training vs Qwen3-TTS ▶ video | NPU (AKD1000), NVIDIA GPU (Qwen3-TTS), Symphony, GPFS |
| Feb 18 | vLLM + GPFS KV Cache Sharing — 16 llm-d algorithms + 15 capabilities reimplemented on Symphony; three-tier GPFS cache replacing Redis; cross-model KV transfer Granite 2B to 8B to 34B | NVIDIA GPU (vLLM), Symphony, IBM Cloud, GPFS (three-tier KV cache w/ ILM) |
| Feb 10 | Akida Behavioral Biometrics — Voice emotion analysis of Palantir earnings livestream; 71μs inference, 89.3% confidence; detected vocal excitement 2-3 seconds before 15x volume spike ▶ video | NPU (AKD1000), Symphony, GPFS, Polygon.io |
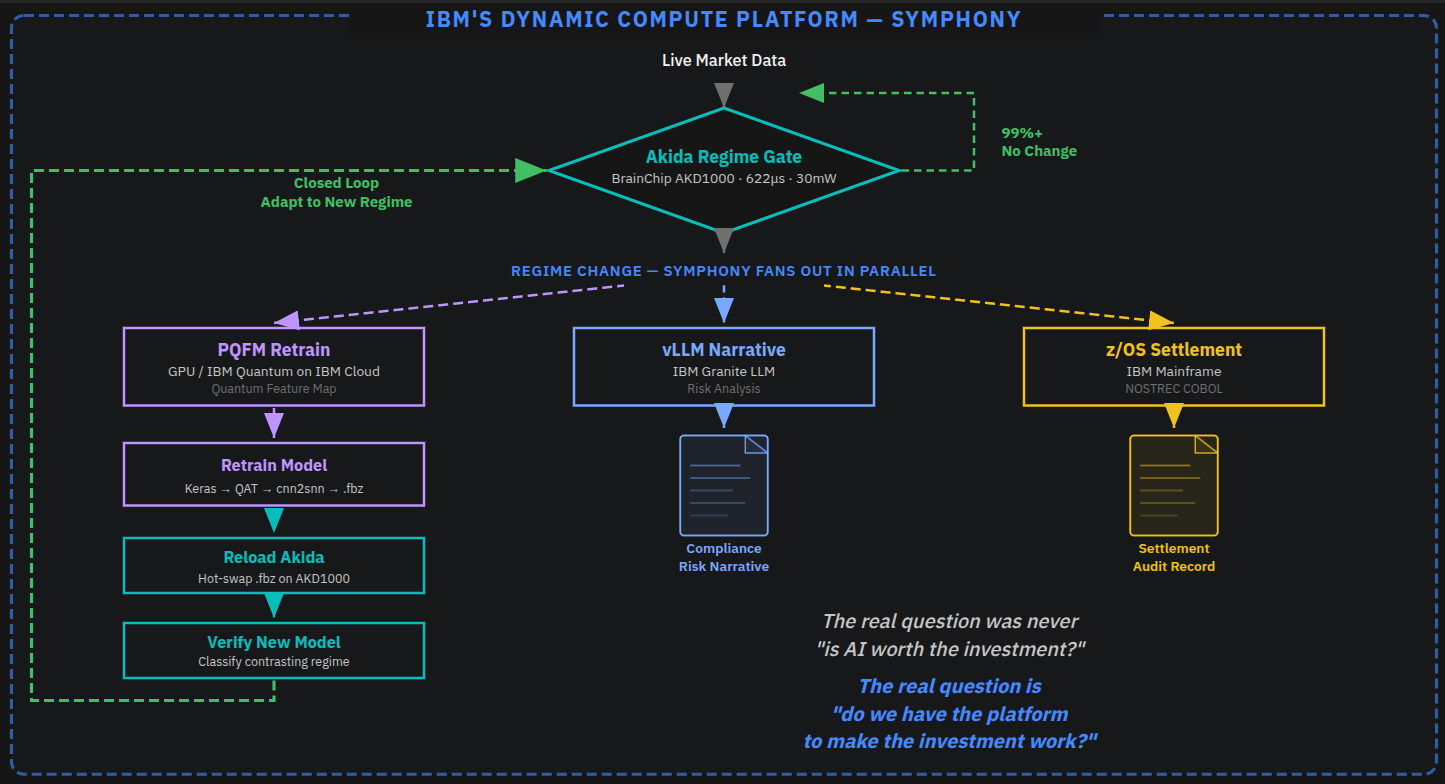
| Feb 7 | Quantum-Neuromorphic Portfolio Pipeline — Four-tier workflow: PQFM quantum feature encoding (16-qubit Heisenberg), Akida regime classification, LLM risk narratives, z/OS COBOL settlement ▸ architecture | QPU (Heron R3), NPU (AKD1000), NVIDIA GPU (vLLM), z/OS, Symphony, IBM Cloud, GPFS |
| Feb 3 | Akida Market Regime Classifier — Real-time market regime classification: 93.47% accuracy, 622μs latency, 30mW on AKD1000 | NPU (AKD1000), Intel N100, Symphony, GPFS |
| Jan 20 | Symphony Mainframe: Conversational z/OS — Natural language interface for COBOL actuarial on Wazi aaS | z/OS (Wazi aaS), Symphony, IBM Cloud |
| Jan 17 | Neuromorphic Symphony: GPU HBM as Storage Tier — Spike-driven data lifecycle with GPFS + DMAPI + Norse LIF neurons | NVIDIA GPU, Symphony, GPFS |
| Jan 12 | Quantum-Classical Integration Suite — Four Qiskit applications on GPU simulation and IBM Quantum Heron R3; 2,560 hyperparameter combinations | QPU (Heron R3), NVIDIA GPU (6x A100), Qiskit, Symphony, IBM Cloud, GPFS |
| Jan 12 | KNN Semantic Router iPhone App Video Demo — Live iPhone/Android app; queries classified and routed across Granite model tiers with ELIM metrics ▶ video | NVIDIA GPU (vLLM), Symphony, GPFS |
| Jan 7 | PowerVS + Symphony Actuarial — Natural language interface for COBOL actuarial programs on IBM PowerVS; no COBOL rewrite required | IBM Power (PowerVS), Symphony, IBM Cloud |
| Jan 6 | Semantic Router / LLM Query Routing — KNN semantic classification routing queries to Granite model tiers for 30-50% cost reduction | NVIDIA GPU (vLLM), Symphony, GPFS |
| Dec 29 | Palantir + Symphony: Cognitive Infrastructure — Ontology Intelligence discovering 1,804 entities and 2,690 relationships from financial services data | Symphony, GPFS, Palantir Foundry, Granite LLM |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
About
I work at the intersection of high-performance computing, AI infrastructure, and the data platforms that hold them together. Most of my career has been spent building and deploying these systems for organizations where downtime or bad answers aren’t an option. That includes financial services, government, defense, healthcare, and research.
I’m a Field CTO at IBM, focused on the HPC Cloud portfolio, which includes Spectrum Symphony, Storage Scale, and LSF. Before that, I spent over a decade in consulting engagements across the same stack. That work covered petabyte-scale parallel file systems, real-time workload orchestration, and the infrastructure underneath large-scale AI. Before IBM, I managed HPC biocomputing infrastructure at TGen, ran a specialty coffee company, and worked in storage virtualization and disaster recovery.
Lately, most of my independent work has been exploring what happens when neuromorphic hardware, large language models, and distributed orchestration frameworks are combined in ways their designers didn’t anticipate. The articles on this site come from that exploration.
I hold an MBA and a Master of Accounting in Finance from Keller Graduate School, an M.A. in Theology from Fuller Theological Seminary, and an M.S. in Global Technology and Development from Arizona State University, where I’m currently a Ph.D. candidate in Innovation in Global Development. My research examines how coordination infrastructure shapes what we can know, decide, and imagine, using computational AI and simulation methods to compare architectures at scale, arguing that infrastructure building is itself a mode of development theorizing.